Clustering O Que É
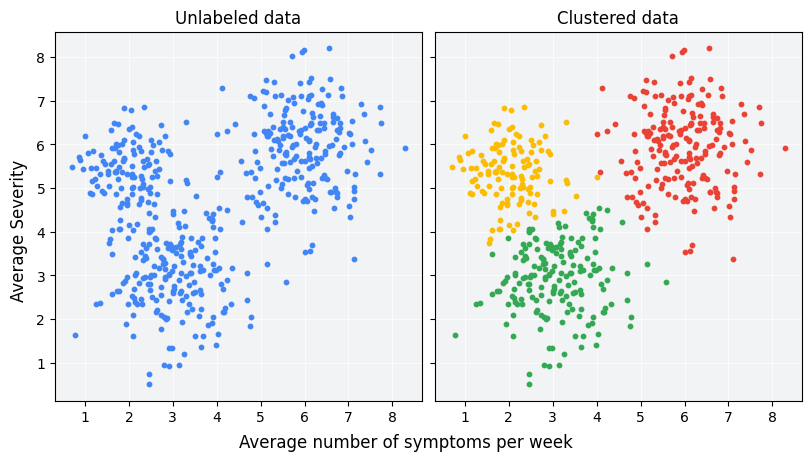
Clustering o que é: técnica de agrupamento de dados que organiza informações em clusters com base em similaridade, sendo amplamente utilizada em machine learning e análise de dados para descobrir padrões sem rótulos prévios.
Definição e conceito básico de clustering
Clustering, ou agrupamento, é um método de aprendizado não supervisionado que separa uma coleção de objetos em grupos chamados clusters, de modo que objetos no mesmo cluster sejam mais similares entre si do que objetos de outros clusters. Diferentemente de tarefas de classificação, o clustering não usa rótulos pré-definidos, sendo útil para explorar estruturas latentes nos dados, como clientes, documentos ou imagens, sem conhecimento prévio sobre os resultados esperados.
Características principais do clustering
- Agrupamento baseado em similaridade ou distância entre os dados.
- Descoberta de padrões e estruturas sem necessidade de rótulos.
- Flexibilidade para aplicar em diversos tipos de dados, como numéricos, categóricos ou textuais.
- Objetivo de maximizar a homogeneidade interna e a heterogeneidade entre os grupos.
- Algoritmos variados, cada um com pressupostos e funcionamentos diferentes.
Como o clustering funciona na prática
O funcionamento de um método de clustering geralmente envolve a escolha de uma métrica de distância, a definição do número de grupos e a aplicação de um algoritmo que otimiza alguma medida de compactação ou separação dos clusters. Em muitos casos, o processo começa com uma ou mais formas de inicialização de centros ou protótipos, seguidas de iterações que reatribuem os pontos aos grupos mais próximos até convergir. A qualidade dos resultados é avaliada por índices internos, como silhueta, ou por validade externa quando se dispõe de rótulos de referência.
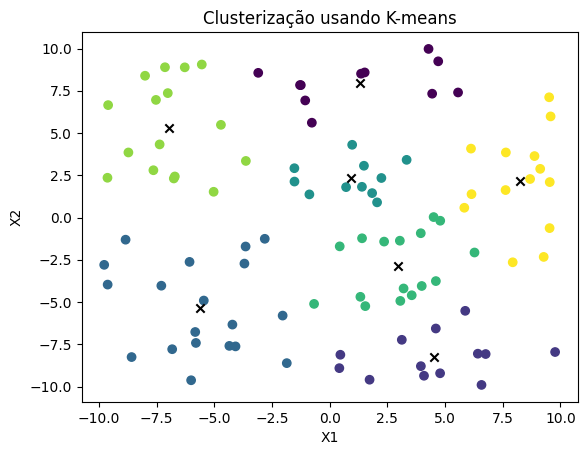
Tipos de algoritmos de clustering mais comuns
- K-means: particiona os dados em k clusters, minimizando a soma das distâncias ao centróide de cada grupo.
- DBSCAN: agrupa pontos densos e identifica outliers, sendo robusto a ruídos e formatos irregulares.
- Hierarchical clustering: constrói uma hierarquia de clusters, podendo ser aglomerativo ou divisivo.
- Gaussian Mixture Models (GMM): modela clusters como distribuições gaussianas e usa probabilidades para alocar pontos.
- Spectral clustering: utiliza eigenvetores de matrizes de similaridade para capturar estruturas não convexas.
Aplicações práticas e exemplos reais
Na prática, o clustering é usado em diversas áreas para organizar informações e apoiar decisões. No marketing, ajuda a identificar perfis de clientes com comportamentos similares para campanhas direcionadas. Em recursos humanos, pode agrupar funcionários por características de desempenho ou competências. Na análise de imagens, técnicas de clustering são aplicadas em segmentação de objetos e reconhecimento de padrões. Já no universo digital, é comum utilizar clustering para organizar tópicos em grandes corpora de texto, facilitar a descoberta de comunidades em redes sociais e melhorar sistemas de recomendação ao agrupar itens com preferências semelhantes.
Resumo dos principais pontos sobre clustering
- Clustering é uma técnica de agrupamento de dados não supervisionada, focada em similaridade.
- Objetiva revelar estruturas internas sem a necessidade de rótulos prévios.
- Envolve escolha de métrica, definição de número de grupos e validação dos resultados.
- Inclui algoritmetros populares como K-means, DBSCAN, hierarchical clustering, GMM e spectral clustering.
- Tem aplicações amplas em marketing, RH, análise de imagens, exploração de textos e sistemas de recomendação.
Perguntas frequentes
Qual a principal diferença entre clustering e classificação?
Clustering é uma tarefa de aprendizado não supervisionado, ou seja, não usa rótulos, enquanto classificação é supervisionada e depende de dados com rótulos já definidos para treinar o modelo.
Como escolher o número de clusters em um projeto real?
A escolha do número de clusters pode ser guiada por métodos como o cotovelo, a silhueta ou domain knowledge, sendo importante testar diferentes configurações e validar os resultados com métricas ou análise de negócio.

O clustering consegue trabalhar com dados de alta dimensionalidade?
Sim, mas a eficácia depende do algoritmo e da métrica de distância; em alta dimensionalidade, distâncias tendem a se tornar menos discriminativas, sendo útil aplicar redução de dimensionalidade, como PCA, antes do clustering.
Clusterização é a mesma coisa que segmentação de dados?
Segmentação de dados é um termo mais geral que pode incluir clusterização, mas também englobar outros tipos de divisão, enquanto clustering se refere especificamente a métodos que agrupam com base em similaridade.
