Data Mining O Que É
Data mining o que é: conjunto de técnicas de ciência de dados que descobrem padrões úteis em grandes volumes de informação por meio de algoritmos estatísticos, de machine learning e de banco de dados, transformando dados brutos em conhecimento acionável para tomada de decisão empresarial.
Na prática, data mining combina engenharia de recursos, modelos preditivos e validação rigorosa para extrair insights que não são evidentes em análises superficiais. Difere da simples consulta SQL porque vai além da busca: ele identifica correlações, clusters, anomalias e tendências em bases que podem ser transacionais, de texto, de sensores ou de imagens. Ao integrar conceitos de estatística, mineração de padrões e inteligência artificial, o campo evolui com o aumento de dados não estruturados e da disponibilidade de computação em nuvem.
Características essenciais
O núcleo de data mining o que é pode ser entendido pelas características que o definem em relação à estatística tradicional e ao business intelligence.
- Volume: lida com bases massivas, às vezes em escala big data, onde o ruído é prevalente.
- Velocidade: processos automatizados que operam em streaming ou em lote para atualizar insights rapidamente.
- Variedade: trabalha com textos, logs, imagens, séries temporais e relacionamentos complexos entre entidades.
- Valor: foca na descoberta de padrões que geram lucro, redução de risco ou melhoria operacional.
- Integridade: utiliza métricas de qualidade, como suporte, confiança e lift, para garantir que os padrões sejam robustos e generalizáveis.
Como funciona na prática
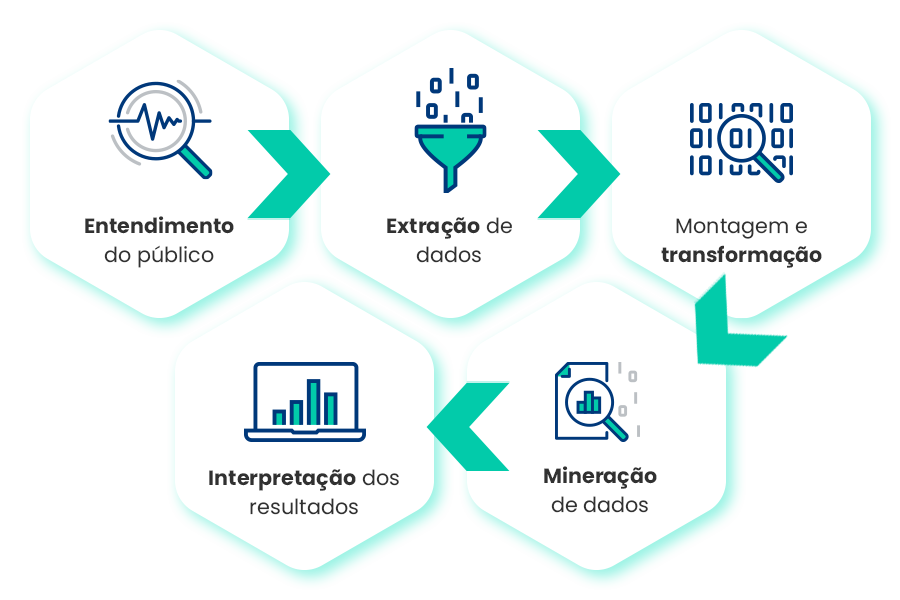
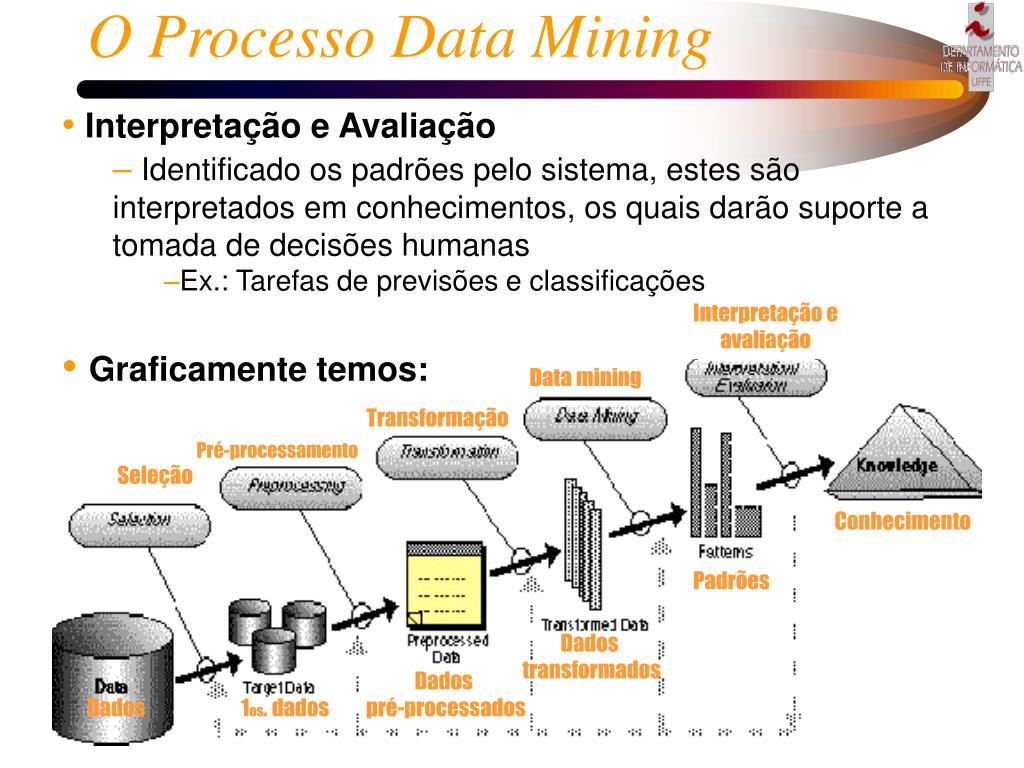
O fluxo típico de um projeto de data mining alinha etapas de engenharia de dados, modelagem estatística e validação de negócios, integrando o conhecimento do domínio com técnicas de machine learning.
Pré-processamento e preparo
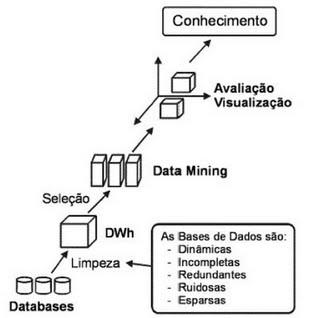
Antes de aplicar algoritmos, os dados passam por limpeza (remoção de duplicatas e inconsistências), integração (junção de fontes distintas) e transformação (normalização, discretização e engenharia de features). É também nessa etapa que se define o escopo do problema, selecionando variáveis relevantes para evitar viés e overfitting.
Mineração e validação
Em seguida, escolhe-se uma ou mais abordagens: classificação para rotular registros, regressão para prever valores, clustering para agrupor casos semelhantes, associação para encontrar coocorrências (como rules de mercado cesta), ou detecção de anomalias para identificar fraudes. Os modelos são avaliados com métricas de acurácia, estabilidade e custo computacional, usando técnicas como cross-validation e holdout sets para garantir que os insights sejam aplicáveis a cenários reais.

Exemplos concretos de aplicação
O escopo de data mining o que é se reflete em usos práticos em setores que dependem de padrões ocultos em grandes bases.
- Varejo: análise de cesta de compras para otimizar merchandising e campanhas de cross-selling.
- Finanças: detecção de fraudes em transações ao identificar desvios em relatórios de gastos e padrões de comportamento.
- Saúde: mineração de prontuários eletrônicos para prever readmissões hospitalares e personalizar tratamentos.
- Telecomunicações: churn prediction para reter clientes com ofertas personalizadas baseadas em uso e satisfação.
- Marketing digital: segmentação de audiência por clusters de comportamento e predição de resposta a campanhas.
Desafios e boas práticas
Implantar data mining eficazmente exige atenção a armadilhas éticas, viés algorítmico e governança de dados, especialmente quando modelos são usados em decisões automatizadas que afetam diretamente clientes e colaboradores.
- Qualidade dos dados: invés de buscar complexidade algorítmica, priorize métricas de qualidade de entrada, como completude, consistência e atualização.
- Interpretabilidade: use SHAP, LIME ou árvores de decisão quando a explicabilidade for regulatória ou relevante para stakeholders.
- Escalabilidade: avalie pipelines distribuídos com Spark ou ferramentas de MLOps para manter performance à medida que os volumes crescem.
- Ética e privacidade: adote anonimização, differential privacy e auditorias de viés para alinhar com LGPD e boas práticas de governança.
Resumo dos principais pontos
- Data mining o que é: é a extração de padrões valiosos de grandes bases por meio de algoritmos estatísticos e de machine learning.
- Características: volume, velocidade, variedade, valor e rigor de validação definem a abordagem.
- Fluxo: envolve pré-processamento, mineração com múltiplas técnicas e validação rigorosa com métricas de negócio.
- Aplicações: varejo, finanças, saúde, telecom e marketing digital usam descobertas para otimizar receita, reduzir riscos e melhorar experiência.
- Desafios: qualidade de dados, interpretabilidade, escalabilidade e conformidade ética são fundamentais para resultados sustentáveis.
Perguntas frequentes
Data mining é a mesma coisa que machine learning?
Não exatamente: data mining foca em descobrir padrões em bases existentes, enquanto machine learning enfatiza a construção de modelos preditivos que generalizam para novos dados, muitas vezes integrando etapas de mineração.
Quais são as diferenças entre data mining e business intelligence?
Business intelligence busca relatórios e indicadores com base em consultas descritivas, já data mining usa algoritmos para prever tendências, agrupar clientes ou identificar regras de associação que não são evidentes em dashboards tradicionais.
Como garantir conformidade com a LGPD em projetos de data mining?
Trate apenas dados com base legal adequada, anonimize ou pseudonimize informações sensíveis, documente finalidades e realize avaliações de risco, garantindo transparência e possibilidade de retificação para os titulares.
Quais ferramentas são comuns para data mining?
Entre as mais usadas estão Python (com pandas, scikit-learn, PySpark), R, SAS, SPSS, além de ferramentas de banco de dados com suporte a analytics, como Oracle Data Mining e soluções em nuvem de grandes provedoras.

