O Que Significa Outlier
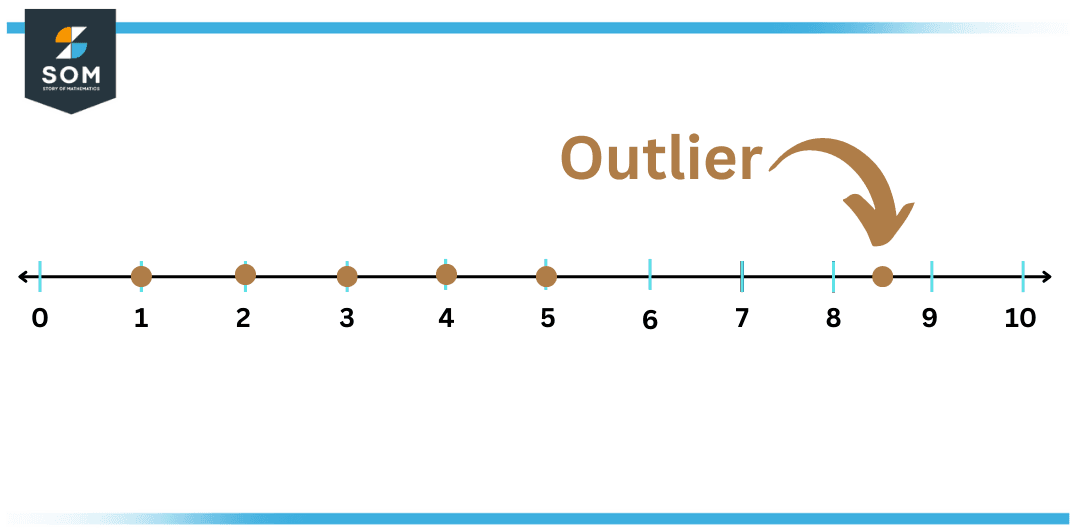
O que significa outlier é uma pergunta comum em estatística, análise de dados e ciência da computação, pois refere-se a um registro ou ponto que se distancia drasticamente do restante das observações em um conjunto de dados.
Essa definição aponta para a essência do conceito: um outlier pode ser um valor extremamente alto ou baixo em relação à distribuição esperada, influenciando medidas de tendência central e variabilidade, como média e desvio padrão, especialmente em contextos de análise exploratória e modelagem preditiva. Antes de mais nada, é crucial entender que um outlier não é necessariamente um erro, mas sim uma observação que merece atenção contextual.
Características principais de um outlier
Para identificar e tratar corretamente um outlier, é preciso conhecer suas propriedades fundamentais. Essas características ajudam a diferenciar um verdadeiro ponto discrepante de um simples valor atípico decorrente de ruído de medição.
- Distância anormal em relação à maioria dos dados, geralmente medida por desvios padrão ou percentis.
- Pode surgir devido a variabilidade natural, erro de coleta, entrada incorreta ou comportamento genuinamente extremo.
- Impacta métricas estatísticas, como média e correlação, podendo distorcer conclusões se não for manejado adequadamente.
- Sua relevância depende do contexto: em alguns estudos, outliers são valiosos para detectar fenômenos raros ou excepcionais.
Como funciona a detecção de outlier em prática analítica?
A detecção de outlier envolve métodos estatísticos, heurísticos e de aprendizado de máquina, que variam conforme o tipo de dados e o objetivo da análise.

Métodos estatísticos comuns
Dentre as abordagens mais tradicionais, destacam-se o uso de regras empíricas, como o intervalo interquartil (IQR) e o método de desvio padrão, que definem limites além dos quais os pontos são considerados discrepantes.
Abordagens baseadas em distância e densidade
Em contextos multivariados, algoritmos como DBSCAN e Local Outlier Factor (LOF) avaliam a densidade local dos pontos, identificando regiões esparsas onde os outliers se localizam em relação aos vizinhos.
Aprendizado de máquina supervisionado e não supervisionado
Modelos como Isolation Forest e Autoencoders são treinados para reduzir a dimensionalidade e isolar instâncias raras, sendo particularmente úteis em grandes volumes de dados não rotulados.
Quais são os exemplos típicos de outlier em diferentes áreas?
Reconhecer exemplos práticos ajuda a solidificar a compreensão do que significa outlier e como ele se manifesta na realidade.

Finanças e mercado de ações
Um volume de transações anormalmente alto ou um salário extremamente discrepante em uma folha de pagamento podem indicar fraudes ou eventos pontuais de mercado.
Qualidade e manufatura
Em linhas de produção, medidas como tempo de ciclo ou defeitos por unidade podem apresentar outliers que sinalizam falhas em máquinas ou erros humanos.
Sensoriamento remoto e IoT
Leituras de sensores em ambientes industriais podem gerar picos devido a falhas técnicas ou condições extremas, exigindo filtros para manter a integridade dos dados.
Por que identificar um outlier é importante para a análise de dados?
Identificar e tratar outlier de forma adequada é essencial para garantir a robustez dos modelos preditivos e a confiabilidade das inferências estatísticas.
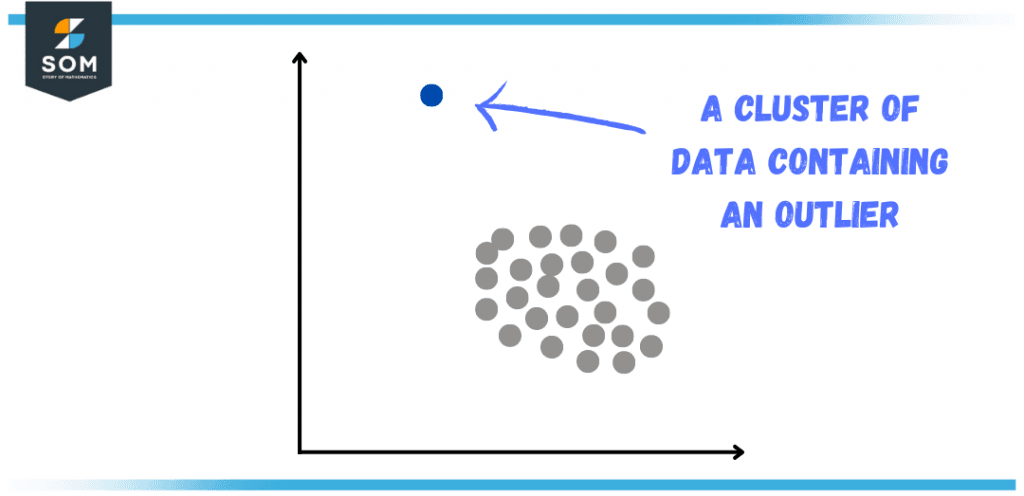
Em muitos casos, a simples remoção desses pontos sem uma investigação cuidadosa pode levar à perda de informações críticas, especialmente quando eles representam eventos reais, como fraudes ou falhas emergenciais. Por outro lado, ignorar um outlier pode distorcer modelos de machine learning, afetando a precisão de previsões em áreas como crédito, saúde e marketing.
Como tratar um outlier de forma eficaz?
O tratamento de outlier depende da origem do ponto discrepante e do objetivo do projeto de análise. Existem estratégias diretas e indiretas, que variam desde a correção até a exclusão ou preservação intencional.
- Verificação de qualidade dos dados para confirmar erros de digitação ou falhas de sensores.
- Transformações matemáticas, como logaritmo ou winsorização, que reduzem o impacto dos valores extremos.
- Modelos robustos, como regressão com perda de Huber, que são menos sensíveis a pontos atípicos.
- Manutenção estratégica quando outliers têm significado prático, como na detecção de anomalias em segurança cibernética.
Qual a diferença entre outlier e ruído nos dados?
Embora frequentemente associados, outlier e ruído não são sinônimos, e distinguir um do outro é vital para uma análise rigorosa.
Enquanto o ruído geralmente representa aleatoriedade ou imprecisão nas medições, um outlier pode ser um sinal legítimo de interesse, especialmente em estudos de cauda longa ou fenômenos extremos. A análise descritiva e o conhecimento do domínio ajudam a classificar corretamente cada caso.

Quais ferramentas ajudam a identificar um outlier com precisão?
Diversas bibliotecas e softwares possibilitam a detecção visual e automatizada de outlier, integrando estatística descrita e métodos computacionais avançados.
- Python: bibliotecas como Pandas, NumPy, Scikit-learn e Seaborn oferecem funções para cálculo de IQR, boxplots e isolation forests.
- R: pacotes como dplyr, ggplot2 e anomalize facilitam a limpeza e a visualização de dados com comportamentos atípicos.
- Planilhas e BI: Excel, Google Sheets e ferramentas de Business Intelligence permitem regras de negócio e gráficos de caixa para inspeção inicial.
Perguntas frequentes
Um outlier é sempre considerado um erro nos dados?
Não necessariamente. Um outlier pode ser um erro de medição, mas também pode representar um evento raro e importante, como uma fraude ou um comportamento extremo, sendo valioso em contextos de detecção de anomalias.
Como escolher o método adequado para identificar um outlier?
A escolha depende da natureza dos dados (univariado ou multivariado), do volume de informações e do objetivo da análise, sendo recomendável combinar métodos estatísticos, visualização e conhecimento de domínio.
Qual o impacto de um outlier na análise estatística?
Outliers podem distorcer medidas de tendência central e dispersão, afetando intervalos de confiança, testes de hipóteses e a performance de algoritmos de machine learning, exigindo tratamento cuidadoso.
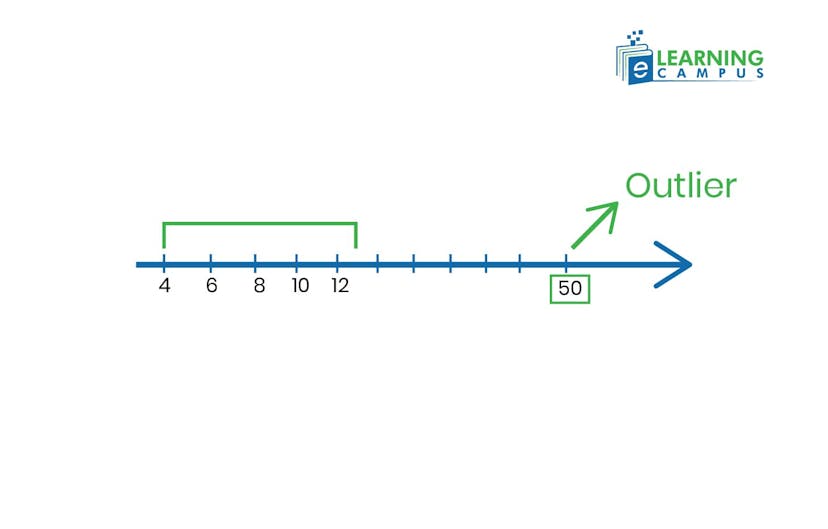
É possível evitar a ocorrência de outlier ao coletar dados?
Embora a qualidade no projeto de coleta reduza erros, outliers naturais são inevitáveis em muitos fenômenos, especialmente em variáveis com distribuições assimétricas ou caudas longas.
